“If you know the enemy and know yourself, you need not fear the result of a hundred battles. If you know yourself but not the enemy, for every victory gained you will also suffer a defeat. If you...
In this webinar Steve Hamby, Managing Director Government, discusses semantic graph technology to help Federal Government CIOs and their agency staff that are researching enterprise data management...
As we approach the end of 2016, we sat down with our CEO, Chuck Pieper, to discuss the future of big data and get his predictions for 2017. Here are his thoughts.
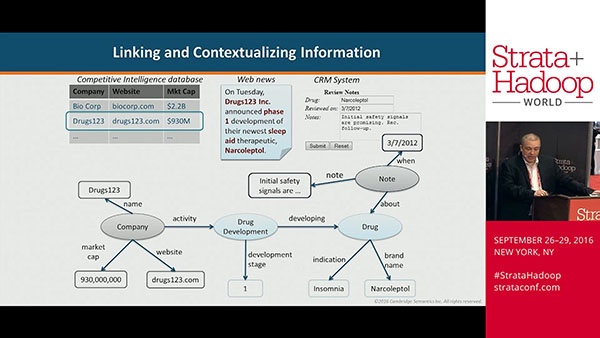
In September 2016 Cambridge Semantics attended Strata+Hadoop World 2016 in New York, NY. While we were there, Marty Loughlin, our VP of Financial Services, spoke to a gathering of attendees about...
Historically, understanding the contents of unstructured text has required a great deal of time and effort by experts to read stacks of documents and manually extract key information that is then...
The challenge for analysts seeking trading opportunities that outperform the market is not a lack of information. It is an over-supply of information from widely disparate sources. How do you sift...
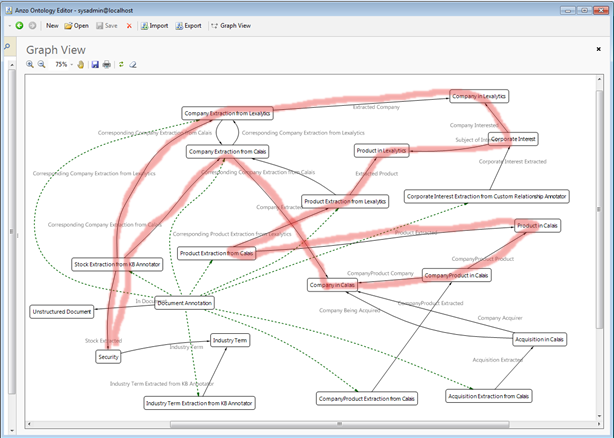
Enterprise text analytics is an exciting and powerful area gaining traction recently. When one moves on from purely departmental solutions to a perspective of an enterprise text analytics fabric,...
The Need Unstructured data is all around us: in news stories, web pages, journal articles, social media posts, patents, research reports, presentations, and a variety of other sources. These items...
Data lakes are no longer anomalies. Consolidating all of an organization’s data—unstructured, semi-structured, and structured—into a single repository for integration, access, and analytics purposes...
Richard Mallah, our Director of Advanced Analytics recently participated at the The Twenty-ninth Annual Conference on Neural Information Processing Systems (NIPS), focused on machine learning and...