We had a great conversation with Ashleigh Faith the other day. Ashleigh is drilling Knowledge Graph vendors with pressing questions from different types of customers that find themselves at an early...
We’re pleased to announce the release of Anzo® 5.3. This is a major release full of exciting capabilities to further enhance the leading knowledge graph platform solution, Anzo. Foremost, it’s now...
Hi there, I’m Emily Kallfelz, a customer success manager at Cambridge Semantics.
Unleashing the power of knowledge is nowadays the most crucial task for enterprises in order to stay competitive. However, knowledge is not just data thrown into a database. It is a complex, dynamic...
I’m Greg West, Principal Presales Engineer at Cambridge Semantics. What drew me to knowledge graphs and Cambridge Semantics was the opportunity to work with a variety of early engagement clients to...
This blog post is taken from the Q&A portion of our recent Knowledge Graph Lightning Demo Showcase. The knowledge graph demo showcase hosted five unique knowledge graph use cases:
Interested in this case study in PDF form... look no further. A Real-World Example in Production Because much of the information stored in modern enterprise data ecosystems comes in the form of...
This post was originally posted on my, Ben Szekely's, Medium blog early in 2020. I recently had several conversations with leaders in the healthcare and retail industries that reminded me how...
At Cambridge Semantics, Inc. my team and I work with a diverse array of customers across such verticals as Life Sciences, Healthcare, Financial Services, Government and Manufacturing. Even though...
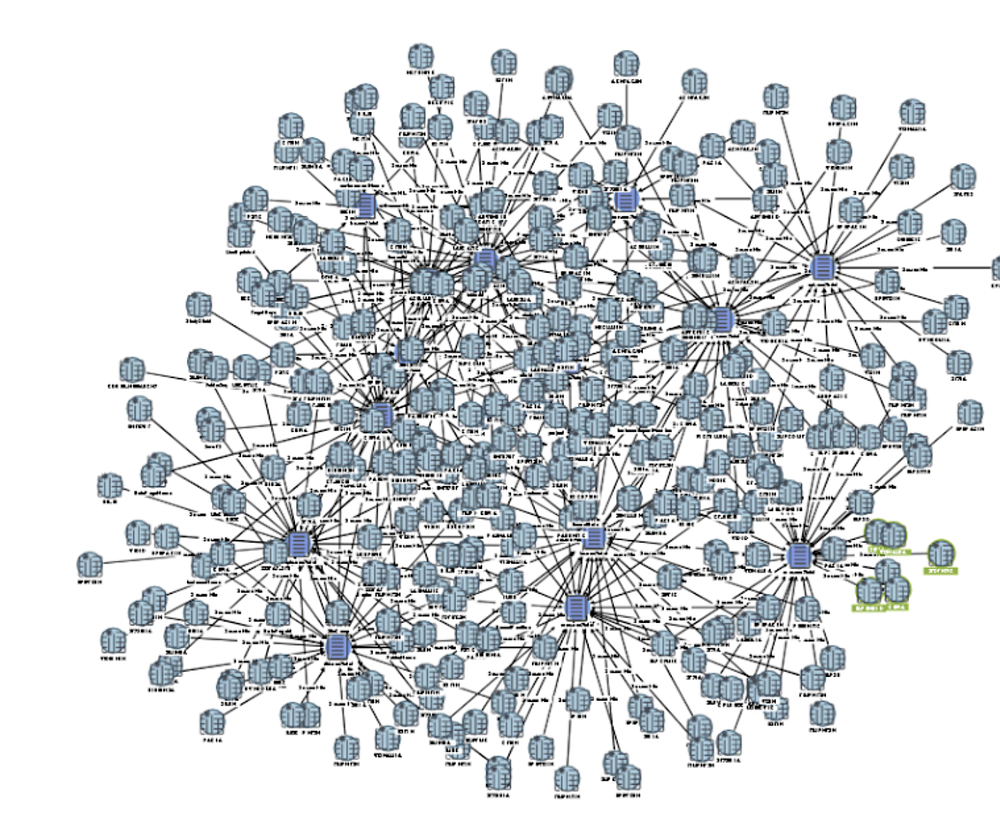
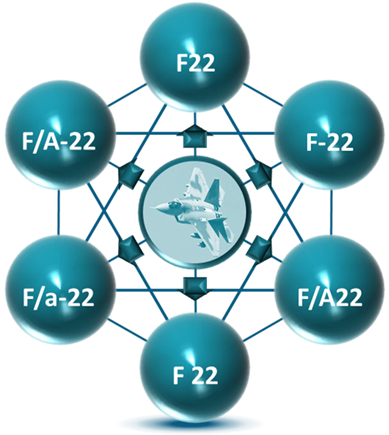
This article describes the concept of the knowledge graph, how knowledge graphs support data interoperability and some of their benefits. The reader will gain an understanding of what a knowledge...


.png)

.png)