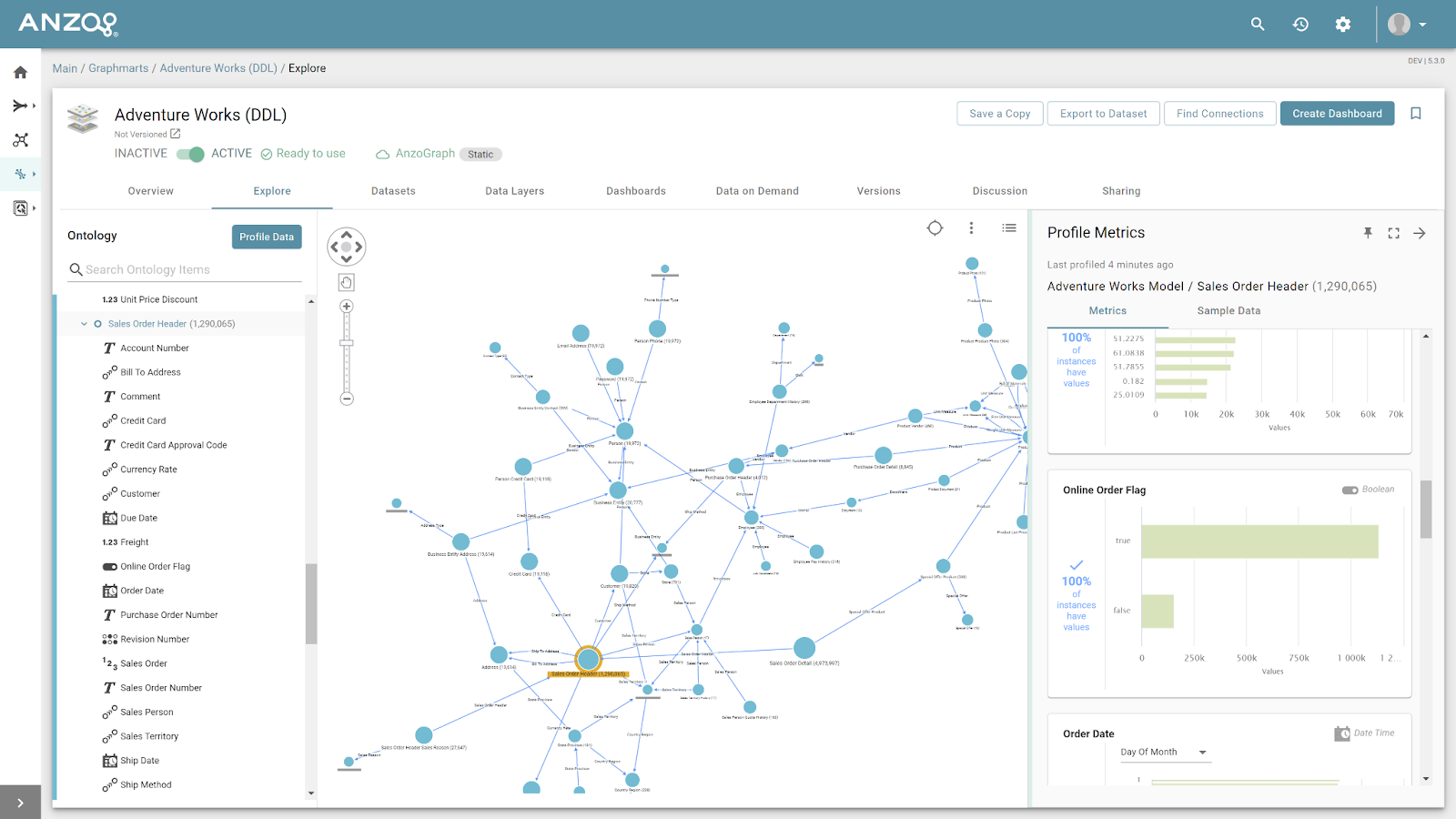
In the rapidly evolving world of artificial intelligence, there's a powerful tool called the Knowledge Guru that is revolutionizing the way we access and utilize enterprise knowledge. This...
We recently held a webinar titled, The Future of Data Integration, where our Principal Presales Engineer Greg West shared why graph technology has become the best solution for data-driven...
Corporate CIOs make dozens of critical decisions every day, and while many will be made with instinct and experience others will depend on deep insight built on data analysis. These decisions not...
In this blog post you will find the documented conversation between myself, Sr. Knowledge Graph Engineer Boris Shalumov, and Knowledge Graph Expert and CTO Sean Martin. Below you will find the...
Interested in this case study in PDF form... look no further. A Real-World Example in Production Because much of the information stored in modern enterprise data ecosystems comes in the form of...
What’s the difference between AnzoGraph compared to Neo4j, Amazon Neptune and many other graph databases on the market? The difference has a lot to do with whether the database is Online...
From the team that developed Netezza and the underlying technology for Redshift, we are proud to provide a free preview on AWS of AnzoGraph, an in-memory massively parallel distributed graph...
Smart Data Lake platforms providing semantic layers are automating data access and data management for accelerated insight. These platforms, based on knowledge graphs, allow organizations on-demand...
An organization’s staff is its most valuable asset, and the human resources function is critical to the stability and growth of business operations.
Real-world events demonstrate our inability to understand rapidly and accurately what we already know. In other words, we cannot answer questions completely, despite the fact that we may hold the...