We recently held a webinar titled, The Future of Data Integration, where our Principal Presales Engineer Greg West shared why graph technology has become the best solution for data-driven enterprises assessing the best data architecture strategies for their future.
This webinar was highly engaged, great questions kept firing in and our team was more than happy to keep answering. To make these questions and answers easier to digest for everyone, they are compiled here.
These are all direct questions from The Future of Data Integration attendees, with direct answers.
List of Questions:
-
Are Neo4j (and other graph databases) not designed for scalability?
-
Does Anzo data onboarding include semantic integrity within and across the data sources?
-
Can the knowledge graph platform be considered “big data” technology?
-
How does search of unstructured data in the knowledge graph work?
-
How much of the full Knowledge Graph pipeline does AnzoGraph cover?
-
Can you speak on Anzo data federations and visualization that is supported?
-
How important is the Ontology design to AnzoGraph's performance?
-
Does Anzo have direct connections to BI tools such as PowerBI and Tableau?
-
Can you if possible speak on Anzo data federations and visualization that is supported?
-
How important is the Ontology design to AnzoGraph's performance?
-
What type of inferencing engine does AnzoGraph currently support?
-
Can you help me with this real world solution I am trying to solve?
Let's dive in:
Question 1
Are Neo4j (and other graph databases) not designed for scalability?
![]() Neo and other graph databases generally have a different design point from Anzo (and its underlying AnzoGraph DB). They tend to be built for transactional style applications (simple queries, small fast record reads/writes/updates) as opposed to data warehouse (OLAP) style access (full table scans, complex queries for transformation and/or analytics) and very fast parallel data load times. While these systems often offer many analytics algorithms, many are simply not suitable for analytics or data transformation queries essential for integrating data in the graph. This quite quickly becomes obvious when the amount of stored data passes a relatively modest threshold or query complexity increases. This blog post dives deeper into the scalability of Anzo vs alternative graph platforms and how one should take these differences into account when determining how well a particular store will perform in your particular application.
Neo and other graph databases generally have a different design point from Anzo (and its underlying AnzoGraph DB). They tend to be built for transactional style applications (simple queries, small fast record reads/writes/updates) as opposed to data warehouse (OLAP) style access (full table scans, complex queries for transformation and/or analytics) and very fast parallel data load times. While these systems often offer many analytics algorithms, many are simply not suitable for analytics or data transformation queries essential for integrating data in the graph. This quite quickly becomes obvious when the amount of stored data passes a relatively modest threshold or query complexity increases. This blog post dives deeper into the scalability of Anzo vs alternative graph platforms and how one should take these differences into account when determining how well a particular store will perform in your particular application.
We should add that AnzoGraph is an MPP (Massively Parallel Processing) engine - i.e. nothing shared, all data sharded out across many compute nodes that execute each query in parallel. This means that additional compute nodes can be added to the compute cluster as needed to handle increasing amounts of data (more storage) or provide more query throughput (by adding more compute). The largest ever cluster we assembled for benchmarking AnzoGraph DB in 2016 on the Google Cloud Platform, comprised of 200 discrete servers each with 64 cpu cores. This kind of MPP architecture is similar to well known RDBMS data warehouse-style systems like AWS RedShift and Snowflake, but was purpose built for handling graph data. And unlike relational systems, AnzoGraph has no fixed schema. This is really handy for bringing in any shaped data to be integrated–including dirty data–and then transforming and linking it into something useful to end user data access or analytics using ELT queries.
Question 2
Does Anzo data onboarding include semantic integrity within and across the data sources?
Not in the same way that a relational schema does using referential integrity (which of course is not necessarily the same as semantic integrity!). AnzoGraph DB is fundamentally schema-less. Instead we use OWL ontology models to describe the data at the conceptual level. OWL metadata is also stored in RDF in the graph, so that ingested data becomes self-describing using the W3C open data standards. The Graph Data Interface (GDI) ETL ingestion sub-system in Anzo maps the data onto OWL models, so that data ingested using it is correctly typed and has been assigned semantic meaning. Currently, we use validation SPARQL queries to validate the data once it is in the graph, although SHACL support will be in the upcoming AnzoGraph DB v3.0 which will provided some extremely useful functionality.
Question 3
Can the knowledge graph platform be considered “big data” technology?
Yes, it certainly can be described as a Big Data system... Or at least the knowledge graph platform, Anzo & AnzoGraph DB, can be considered big data technology since they are based on an MPP architecture. Which means Anzo can scale up in parallel like most other Big Data systems do, and indeed it performs load, transform and analytics operations many times faster than other big data systems like Apache Spark can.
Question 4
What are the most compelling breakthroughs in UX design for making knowledge graphs make sense and explorable for non-technology, non-graph practitioners — such as Physicians
Data Exploration is one of the sweet spots for the Anzo platform. One area that we think is underrated, is Anzo’s ability to use visual OWL model exploration to generate (really complex) queries in our Hi-Res codeless dashboarding tool. Knowledge Graph models can become very elaborate when describing really complicated data fusions, which would make graph query writing very hard if we were not doing this automatically for users under the covers. Another very useful UX design feature in Anzo is the automatic data profiling which results in a UX that allows users to very quickly understand the nature of all the data in their knowledge graph and how it is connected together.
Question 5
How does search of unstructured data in the knowledge graph work? What about Semantic search?
Great question. We have a very tight integration with Elasticsearch. Greg covers this in the webinar. In Anzo, you can use the graphmart to generate custom Elasticsearch indexes and query them, via Anzo, in a federated manner. These queries combine the speed of the inverted index of Elasticsearch and the power of parallel graph OLAP queries provided by AnzoGraph DB, in the same analytics and/or search query.
The way it works is that an Elasticsearch server is queried as a SERVICE from SPARQL and results of this sub-query are joined against data in the KG. This pattern of access is becoming very popular with our customers who are looking to do far more with their text oriented data than has previously been possible with just enterprise search solutions.
As the cost of training custom Machine Learning models continues to decrease, we are increasingly seeing facts, entities and relationship extracts from texts becoming part of the knowledge graph, while at the same time linking back to the documents from which they were obtained. All of this information, including full text indices, can then be used in queries. The hedge fund surveillance example covered in the webinar does this with a mountain of email, presentations, reports and instant message data along with masses of structured data including many years of recorded transactions, stop-lists, entry card swipes, phone call logs.
The GDI is used to fully integrate Elasticsearch with Anzo. Under the covers it does this by federating SPARQL queries into subqueries that are automatically turned into a series of ElasticSearch push-down queries. The results of these queries are then rapidly returned over multiple parallel connections to the graph engine cluster server nodes where they can be joined against any data in the graph. The GDI is used to create and maintain custom Elasticsearch indexes using either data from the knowledge graph or data from any data source the GDI can connect to.
Question 6
Is AnzoGraph interoperable?
Yes on a couple of levels. We are totally based on W3C open data standards: RDF, OWL, SPARQL and support OData for BI tool interoperability. At a deeper level, we have UDX interfaces for third party programers to create custom UDA's, UDF's, UDP's and UDS (User defined Services) in Java and C++ which allows for almost limitless interoperability. For example, the GDI subsystem in AnzoGraph DB is itself a very sophisticated UDS that provides two way connectivity to many different data sources including RDBMS, HTTP REST services and even streaming services like Kafka.
Anzograph DB also directly supports the Apache Arrow standard for importing and exporting large data sets from programs in Big Data ecosystems like Apache Spark, Tensorflow, R, Python, etc. and can read/write Parquet formatted data.
Question 7
How much of the full Knowledge Graph pipeline does AnzoGraph cover?
We believe the entire thing, soup to nuts!
Unlike many graph systems which tend to be a final destination for data that has already been pre-integrated using ETL, Anzo is itself a platform for the integration of the data into a knowledge graph. It does this intially by directly ETL’ing the data from remote sources into the graph using AnzoGraph DB’s GDI extension. Data engineers write SPARQL queries that bring the remote data into the graph and then they go on to complete the job using ELT queries to clean up, link up and massage data into the form best suited for access by the business. All of this is controlled by our novel “graphmart” building interface” which manages all the information manipulation in Anzo in a pattern we call “data layers”. Over and above all of that, we also provide the tools for data access and analytics like our codeless Hi-Res dashboarding tool that automatically creates the underlying complex graph queries and the visual REST data end-point builder.
Question 8
With regard to Semantic Integrity Services, Anzo would require interoperability with such services external to the native knowledge graph?
We believe the various UDX programming interfaces in Anzo/AnzoGraph make this easily achievable, if it is not already possible at a higher level using the various forms of integration provided by the GDI sub-system and the native AnzoGraph DB features. We would need more specific information about the integration required to better advise.
Question 9
How is the metadata integrated? Do you apply ontology integration algorithms? If so, do you use machine learning algorithms for that? How do you ensure that the alignment is perfect (as ML algorithms can make inaccurate predictions)? Do you use manual intervention or some accuracy guaranteeing heuristics to ensure that the integration is perfect?
As with most data integration approaches there is a combination of automation to do the “heavy lifting” and manual intervention to finesse the details that cannot be tackled automatically.
Often users will start by using the GDI to generate an ontology from the data and schema metadata in the remote data source. This approach gets the data into the graph where other algorithms and techniques can be applied using the brute power of the MPP graph engine. For example, the “Find Connections” capability uses another set of techniques to suggest potential matches between node types (classes) in the graph as well as generates the ELT query that can be run to instantiate these new linkages. A data engineer may also create their own model and either map incoming data to that model in a GDI ETL operation or use in-graph transformations (ELT queries) to map data in the graph to their perhaps more business friendly model.
Question 10
 Does your knowledge graph contain the metadata (schema information) as an ontology, or do you also store the instance data into the knowledge graph? Do you integrate the schema (ontology) or the instances (actual tuples) in the knowledge graph?
Does your knowledge graph contain the metadata (schema information) as an ontology, or do you also store the instance data into the knowledge graph? Do you integrate the schema (ontology) or the instances (actual tuples) in the knowledge graph?
The answer is that both ontology information and the instance data are stored together in the graph - and far more!
In fact, all available data including metadata like ontologies, the customer’s own external metadata from 3rd party systems (e.g. reference data or quality metrics), provenance data created during extraction and further processing (sources & targets, transformations, agent), all technical metadata available from a source (e.g. source schema, tables & keys, directory & file names and their sizes, permissions & ownership etc.), and when it is brought into the graph all of the instance data too.
Finally, there is also the derived metadata and new instance data, for example as a result of extensive data profiling (again the power of the MPP engine means we can afford to run a battery of queries that explore the data automatically to provided very detailed profiling metadata) and other analytics as well as derived instance data resulting from ontological inference, machine learning predictions and graph and statistical algorithms.
Co-locating and integrating all of these forms of data in the same knowledge graph makes the transformation of instance data (for cleanup or reshaping or analytics) much simpler since one can take advantage of all that metadata in query rules if it is helpful to the integration. It is also surprisingly often useful for analytics.
Question 11
Can you if possible speak on Anzo data federations and visualization that is supported?
Anzo supports virtualization and data federation using the GDI and AnzoGraph DB’s VIEW mechanism. Anzo’s Hi-Res codeless dashboarding facility can be used to create custom visualizations for analytics and reporting purposes.
Question 12
How important is the Ontology design to AnzoGraph's performance?
Not important in most cases. In AnzoGraph DB, an ontology is not a schema like you need in RDBMS and some graph stores, it is simply more data that describes the stored triples. Also there are no indexes to worry about. However, sprawling ontologies can make queries harder to write and tend to be more difficult for users to understand and navigate.
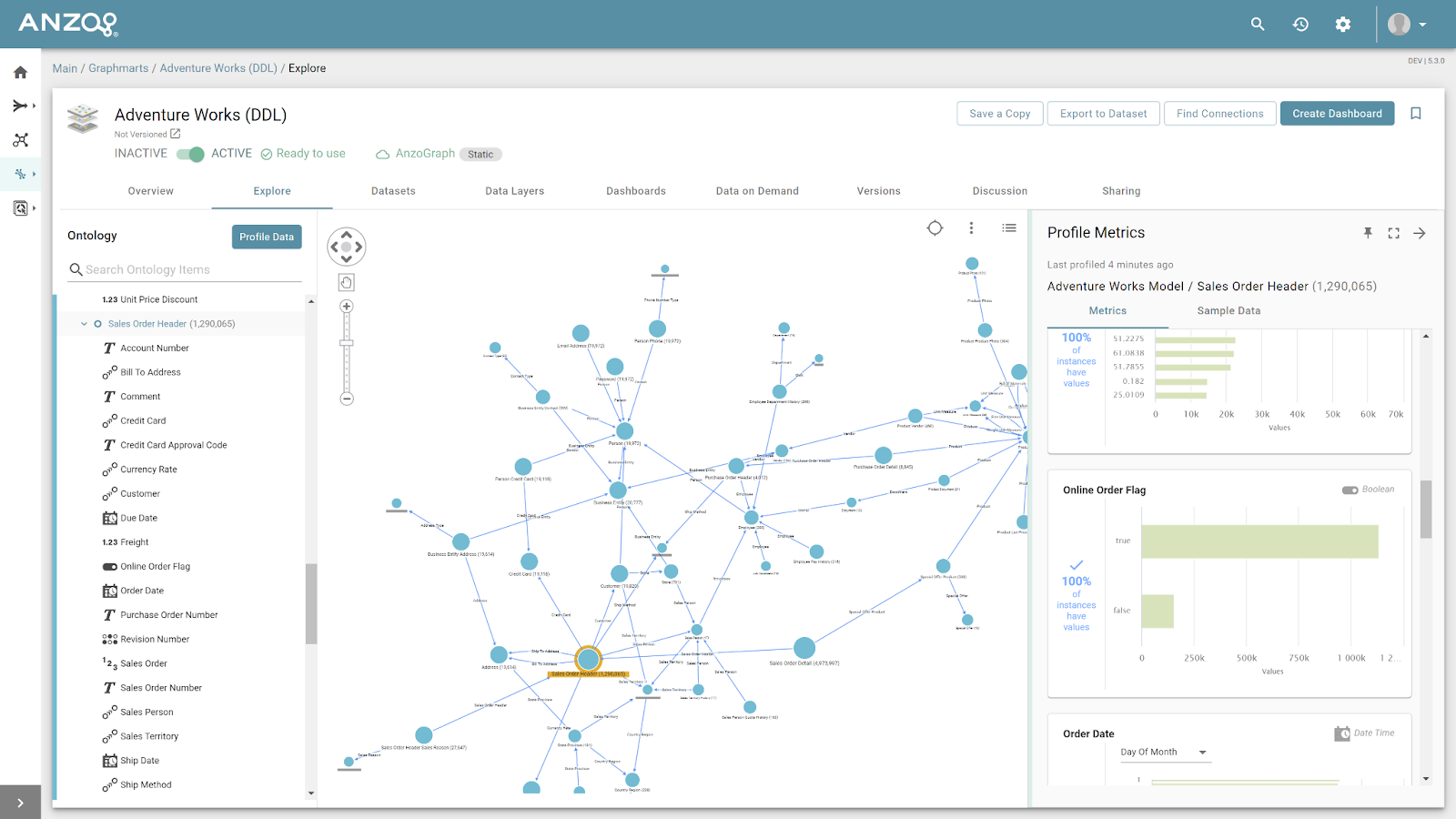
Question 13
How long does it take to generate the full knowledge graph?
It can be very quick indeed, especially if you invoke Anzo’s fully automated ETL facilities and use a single SPARQL query instructing the GDI to "lift up" into the graph an entire (many tables worth of) relational database in parallel.
One instructive example is something we used while testing, the Microsoft AdventureWorks sample database residing on an MS SQL server.. The ETL query needed to bring all that data into Anzo achieves the following result: On a Lenovo laptop it takes about 98 seconds to ingest into the knowledge graph all 68 tables, generating a total 96,924,885 triples across 6,870,519 entities, averaging approximately 989K triples / sec. Obviously this is not a very large amount of data for Anzo to handle, but it is reasonably complex structurally and would take a very long time to map the data into the knowledge graph one table at a time. Here is a screenshot of the model automatically generated after ingestion and data profiling.
Question 14
Does Anzo have direct connections to BI tools such as PowerBI and Tableau?
Both. Most BI tools and MS Excel now support the OData standard and Anzo provides a codeless query builder for defining OData endpoints that can be used to extract information from the knowledge graph by these tools. In some cases the integration goes even further, for example Anzo can generate a Tableau Hyper file or export data directly into a target Tableau Server (via REST API) via a query to the graph engine.
Finally, the platform also supports the Apache Arrow standard for importing and exporting large tabular data sets to/from Big Data ecosystem tools like Apache Spark, Tensorflow, R, Python Pandas etc.
Question 15
Is the knowledge graph generated from the columns names of SQL tables? Does Anzo help tag 1000's of tables with the semantic meaning of each column?
Yes, this is fully automatic by default when extracting data from an RDBMS, but these can be transformed (we call it “normalization” through rules - e.g. camel casing, using dictionaries, detecting where spaces should be etc.) into something friendlier for end users to view. Users can also map data directly onto their own ontologies if they choose. Most use cases do a bit of both styles.
Question 16
In the end-point, does Anzo support emerging standard models as GraphQL ( and RDF* and SPARQL*) ? and also is it possible to use SHACL?
AnzoGraph DB already supports RDF* & SPARQL* and SHACL will be available in the next major release of Anzo.
As for GraphQL, Cambridge Semantics’ product management is actively debating the addition of GraphQL (as a supplement to the OData endpoint capability) in a future release, although we do observe this standard is better suited to supporting applications that need a mix of data type results from a graph in order to display them ( e.g. directors and their films) than it is for describing complex data transformation and analytic queries which is what Anzo is mostly used for. In the meantime, there are plenty of open source options out there which will provide a GraphQL mapping onto Anzo’s SPARQL endpoint.
Question 17
Can a graph query do a push-down OLAP aggregation query in a sub-database as part of the graph query?
Yes, Anzo can. SPARQL sent to the GDI service in AnzoGraph either directly or abstracted via a VIEW, will automatically generate multiple SQL queries targeting a table and push them down and attempt to do so in parallel to the extent RDBMS connections to the underlying system are available and a suitable index can be found. If there is no index on the table, then only a single SQL query is generated, which can be a bit slower. You can also send the GDI specific SQL to federate to a remote source, which could be to perform an aggregation if that's what the data engineer wants. Incidentally, the same kind of generated parallel push down queries are created for Elasticsearch sources using its search API JSON query language format.
That said, AnzoGraph DB is a very scalable and highly performant OLAP database in its own right. Think of it as the first data warehouse for graph data. We have extended its SPARQL 1.1 support with all the capabilities you would expect for warehouse-style reporting & analytics including windowed aggregates and grouping etc., as well as more specialized functions to support data science, graph algorithms and geospatial applications.
 Question 18
Question 18
Is the integration done automatically or do you require the human user to specify how the diverse schema columns are connected to each other? How do you guarantee the accuracy of the integration?
Much of the integration is done automatically through no-code or low-code options. For more complicated integration, power users can define custom SPARQL queries or use other available features. Users have a number of tools to auto-generate connections as well as data profiling to evaluate the accuracy of the generated knowledge graphs. In many cases the automation can produce excellent results and cut down enormously on tiresome mapping tasks.
However, as with all of today’s automation available in the field of data fusion, you will likely still need to keep a human in the loop, The Anzo platform is designed to assist a data engineer be far more efficient with their data integration tasks and data product creation than we believe is currently possible using more traditional approaches. Knowledge Graphs, or rather Anzo, is designed to be the future of data integration.
Question 19
What type of inferencing engine does AnzoGraph currently support?
Question 20
I want to build a big data hub in each geographic area and link them together as a network? Is Anzo a good solution for this?
This sounds like an excellent application for the Anzo platform. Please come and talk to us about it!