In the ever-evolving data integration landscape Cambridge Semantics has emerged as a frontrunner. This is in large part due to the forethought of building a software platform, Anzo, that is...
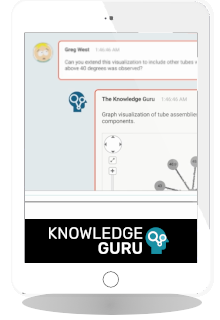
In the rapidly evolving world of artificial intelligence, there's a powerful tool called the Knowledge Guru that is revolutionizing the way we access and utilize enterprise knowledge. This...
An organization’s staff is its most valuable asset, and the human resources function is critical to the stability and growth of business operations.
“If you know the enemy and know yourself, you need not fear the result of a hundred battles. If you know yourself but not the enemy, for every victory gained you will also suffer a defeat. If you...
The complexity of data management and advanced analytics is daunting to many organizations, but a new emerging class of software enables companies to spend less time managing their data and more...
Historically, understanding the contents of unstructured text has required a great deal of time and effort by experts to read stacks of documents and manually extract key information that is then...
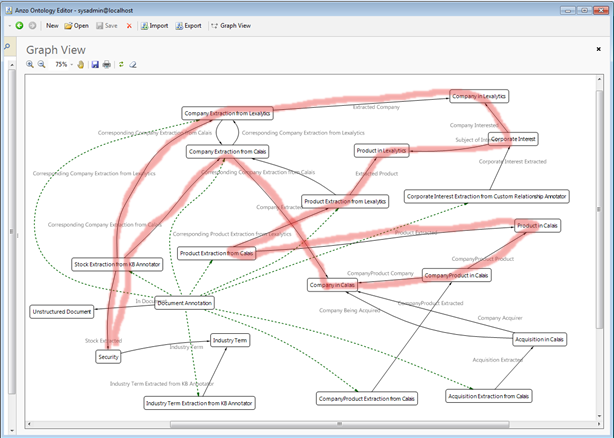
Enterprise text analytics is an exciting and powerful area gaining traction recently. When one moves on from purely departmental solutions to a perspective of an enterprise text analytics fabric,...
The Need Unstructured data is all around us: in news stories, web pages, journal articles, social media posts, patents, research reports, presentations, and a variety of other sources. These items...
Richard Mallah, our Director of Advanced Analytics recently participated at the The Twenty-ninth Annual Conference on Neural Information Processing Systems (NIPS), focused on machine learning and...
When I went to Text Analytics World in San Francisco earlier this month, I was struck at how many of the presenters, particularly consultants, ended their talks describing future directions of text...