Most large financial organizations are wrestling with fundamental data management challenges. Traditional technologies are struggling to meet these challenges and they demand a new approach. Forward thinking organizations are deploying semantic Knowledge Graphs as a powerful option.
This is not just an academic exercise. Enterprise class platforms for operational knowledge graphs are available today. However, transformation takes time, and the time to start is now. The good news is that it is both possible and recommended to start small. Early adopters are selecting targeted, high-impact, uses cases to demonstrate capabilities, realize business value and to build organizational capabilities. In this article, we discuss some of these use cases.
In simple terms, the goal of data organizations is to provide business users with the data they need, when they need it. The data must be timely, of high quality and well governed. The challenge is that the data doesn't come from just one place. It comes from many diverse sources, in various formats, with different names, from inside and outside of the enterprise. Legacy processes and technologies are struggling to meet this challenge and a new approach is required. Leading organizations are looking to semantic graph technology to solve this problem.
A semantic graph or knowledge graph is a conceptual model of the world that is also intuitive to understand: entities, their properties and their relationships. The Financial Industry Business Ontology (FIBO) from the EDM Council is an example of a business conceptual mode for the Financial Industry. Some advantages of a model like FIBO is that it gives us a common vocabulary and meaning for key concepts and terms - a lingua franca or rosetta stone for the industry and regulators. It also gives us a way to describe (and harmonize) our data in a way that is independent of any physical source.
As depicted below, we can use the conceptual model to harmonize data from diverse sources and to create governed data sets for business use case consumption. At Cambridge Semantics, our Anzo platform makes this approach operational at enterprise scale. And, since it is based on W3C open graph standards, it natively supports industry models like FIBO and CDISC.
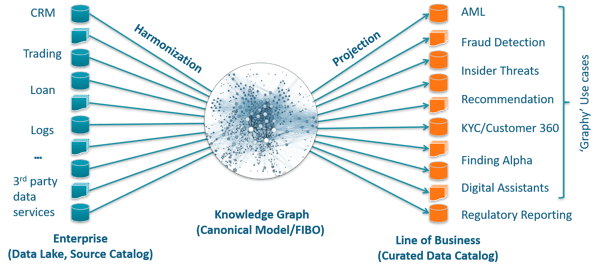
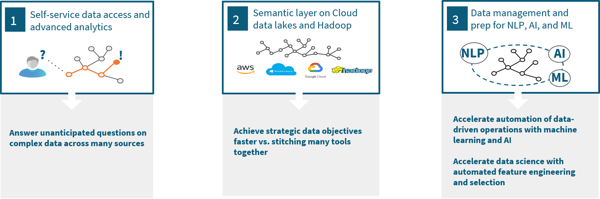
We see three key deployment patterns for semantic data fabrics:
- To provide self-service access to complex data across many sources
- To provide a semantic layer of business meaning and data management on data lakes
- To accelerate and automate data preparation for AI and ML
Here are some real world example use cases for enterprise Knowledge Graphs:
Use Case: Alternative Data for Analytics and Machine Learning
Hedge funds and banks are exploring machine learning and alternative data sets to find new sources of Alpha. The number of new data sets is expected to grow from hundreds today to thousands over the next few years. The diverse formats and sources of these data sets means that they are difficult to on board and to integrate. A Knowledge Graph can streamline and accelerate this process. We are working with our partner, Motive Partners, to demonstrate this capability.
The following example is from the airline industry and includes Airline stock prices, on time arrivals and social media sentiment among other data sources.
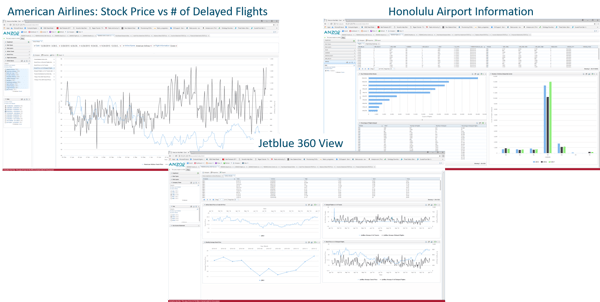
The Knowledge Graph enables integration of these sources without coding and allows analysts to explore the data from any dimension without knowing specific questions in advance. It also supports the preparation of features to feed to ML and AI applications.
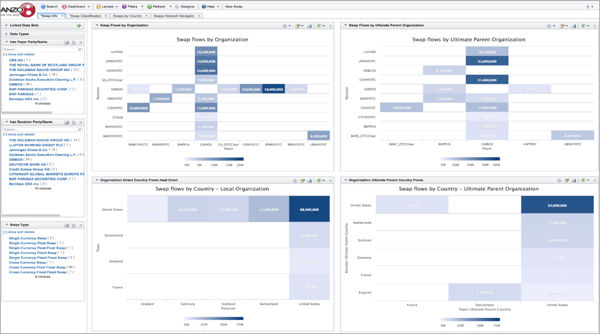
Use Case: Interest Rate Swap Risk Analytics
In 2016, State Street Bank, The Council, Wells Fargo, Dun & Bradstreet and Cambridge Semantics collaborated on a proof of concept project to demonstrate a couple of key objectives:
(1) The practicality of using FIBO to harmonize diverse derivative and entity data
(2) The usefulness of FIBO for comprehensive reporting and analytics, both traditional and innovative
Key business findings included:
Rapid data harmonization across disparate sources
- Open standards approach means model (FIBO) and tools (Anzo) work together seamlessly
- Data mapping, loading, harmonizing and analytics required no coding
Business friendly
- Models and tools are designed for business users – dashboards
- Provide common view of data in business terms
Sophisticated reporting and analytics
- Easily ask questions of the data not anticipated in advance
- Visualize and calculate transitive exposures which would require custom coding with traditional approaches
Business agility
- Rapidly add new sources (internal or external) and analytics
You can read an overview of the project and findings here (via SlideShare).
Use Case: Trade Surveillance
The bane of the trade surveillance world is false positive alerts. Each business and technology island generates alerts and, in most cases, they are benign. The challenge is to discover those cases where there is a pattern of activity that generates a higher risk score across multiple domains.
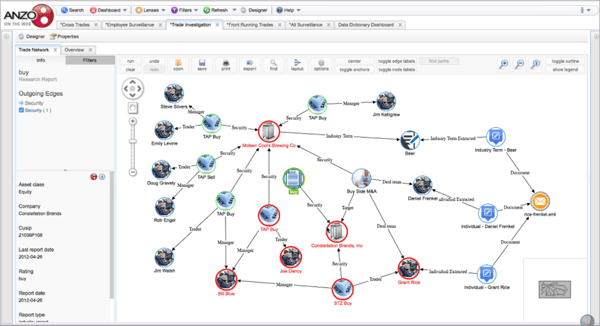
With our partner, PwC, we developed a solution that allows organizations to look at risk across multiple domains. In this example, we are looking at trading activity, restricted lists, watch lists, HR data, email communications, news stories, research reports and deal teams.
Harmonizing data across these diverse sources allows aggregation and elevation of risk based on complex patterns. It also facilitates easy exploration of data, as in the case below, where we display all of the different connections between two traders of interest.
Use Case: Fraud Analytics
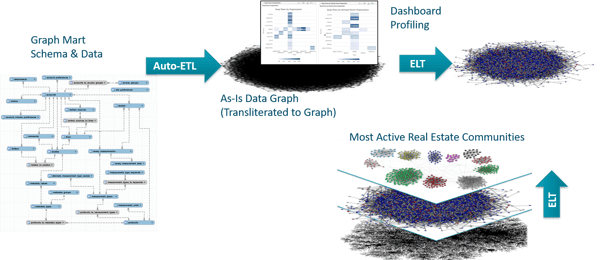
A powerful application of Knowledge Graphs is the transformation of transactional data into a social/entity view. In this case, we transformed property transactions into a Knowledge Graph that contains buyers, sellers, brokers, financial institutions etc.
From this view, we were easily able to identify groups of individuals doing frequent transactions among themselves, for cash - groups worthy of further investigation for fraud.
This pattern of transformation is a powerful way to profile any kind of transactional data.
Use Case: Feature Engineering & Selection
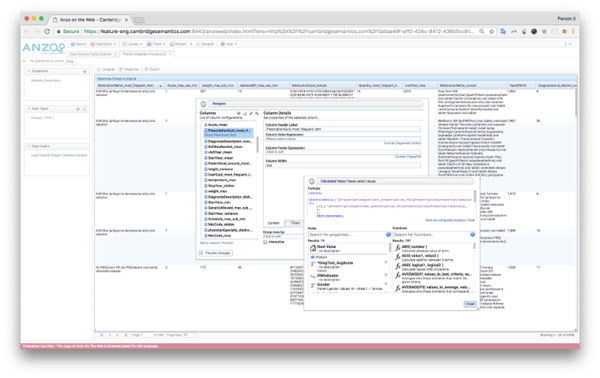
Knowledge Graphs offer a range of advantages for preparing data for and making it operational for AI and ML. Capabilities in Anzo include:
- Web-based interface uses the Knowledge Graph with linked data sets to easily create & select features for machine learning frameworks
- Anzo’s Excel-like formula language makes it easy to de-normalize, aggregate, query, & bucket data from multidimensional models
- Set up rules to clean & transform data
- Keep transformations discrete and granular
- Preserve traceability
Use Case: Data Migration
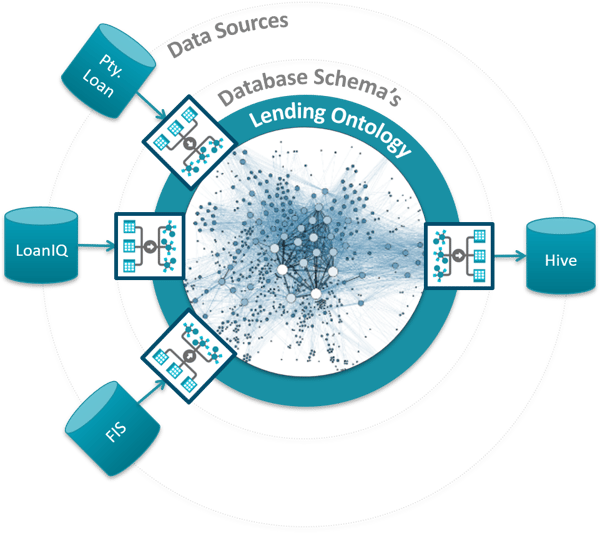
One of the most powerful applications for semantic Knowledge Graphs is data migration: Populating a data lake, consolidating mortgage systems or on-boarding new data feeds are all examples of this capability.
Using a Knowledge Graph creates a hub and spoke model that dramatically reduces mapping effort. In addition, ETL code-generation eliminates the need for coders, creates self-documenting ETL and reduces maintenance costs by an order of magnitude.
For example, for a Data Feed On-Boarding use case, we documented the following business case:
Before
- Multiple SMEs
- 6-12 months to add new feed
- $500K - $1M
After
- Single SME
- 1-3 months to add new feed
- $50K - $100K
Conclusion
- Today’s data challenges need a new approach
- Semantic knowledge graphs are a powerful option
- Enterprise class platforms are available today
- Transformation takes time, start now
- Start small, select meaningful use cases that demonstrate business value and facilitate organizational skill development
To learn more about how Financial Institutions can utilize "semantic engineering" to improve operational efficiencies and increase data transparency, download our whitepaper "Leveraging Semantic Technology to Tame the Enterprise Data Storm".

This article was originally posted to LinkedIn.