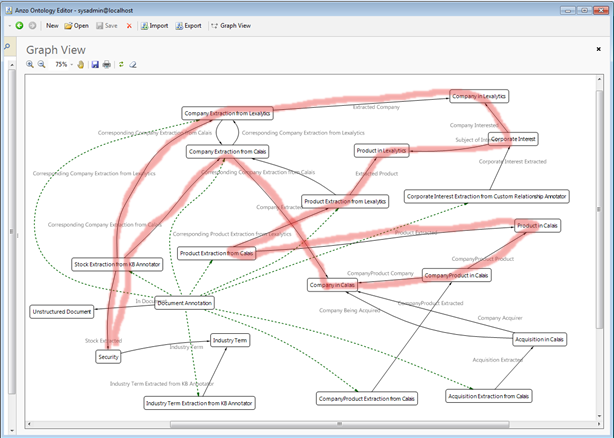
Enterprise text analytics is an exciting and powerful area gaining traction recently. When one moves on from purely departmental solutions to a perspective of an enterprise text analytics fabric,...
The Need Unstructured data is all around us: in news stories, web pages, journal articles, social media posts, patents, research reports, presentations, and a variety of other sources. These items...
When I went to Text Analytics World in San Francisco earlier this month, I was struck at how many of the presenters, particularly consultants, ended their talks describing future directions of text...