I thought I need SHACL, SWRL, ShEx, SPIN, R2RML and more to handle a Semantic RDF Graph - I was proved wrong
Knowledge graphs have become more and more popular due to their unprecedented efficiency in:
- Integrating data from many sources with different data schemas,
- Handling dynamic, redundant, incomplete and inconsistent information and
- Their ability to reason, validate and deduce new knowledge from existing facts.
However, high expressivity, schema flexibility and the open-world assumption (OWA) can sometimes be hard to handle. Thus the W3C Community developed various standards to perform mappings, deduce new knowledge, add closed-world rules to them or check their consistency. But the variety of standards requires a deep understanding of the mechanisms behind them and can make maintenance of the different layers somewhat chaotic.
But is there a way to just use one language? Just one single standard the user has to learn to handle every aspect of a Knowledge Graph? Yes, there is. In its flagship product “Anzo”, a holistic Knowledge Graph Platform, Cambridge Semantics Inc. implemented an interesting concept: Graphmarts.
Essentially, a Graphmart is a collection of data sets and data manipulation steps. Within a Graphmart a user can perform any operation including data mapping, validation and reasoning without using anything but SPARQL. However you can’t just write SAPRQL queries - you need to save them, version them and create a procedure that would put them in order for execution. Graphmarts complement SPARQL by providing the ability to define procedures, templates, versions and user specific views.
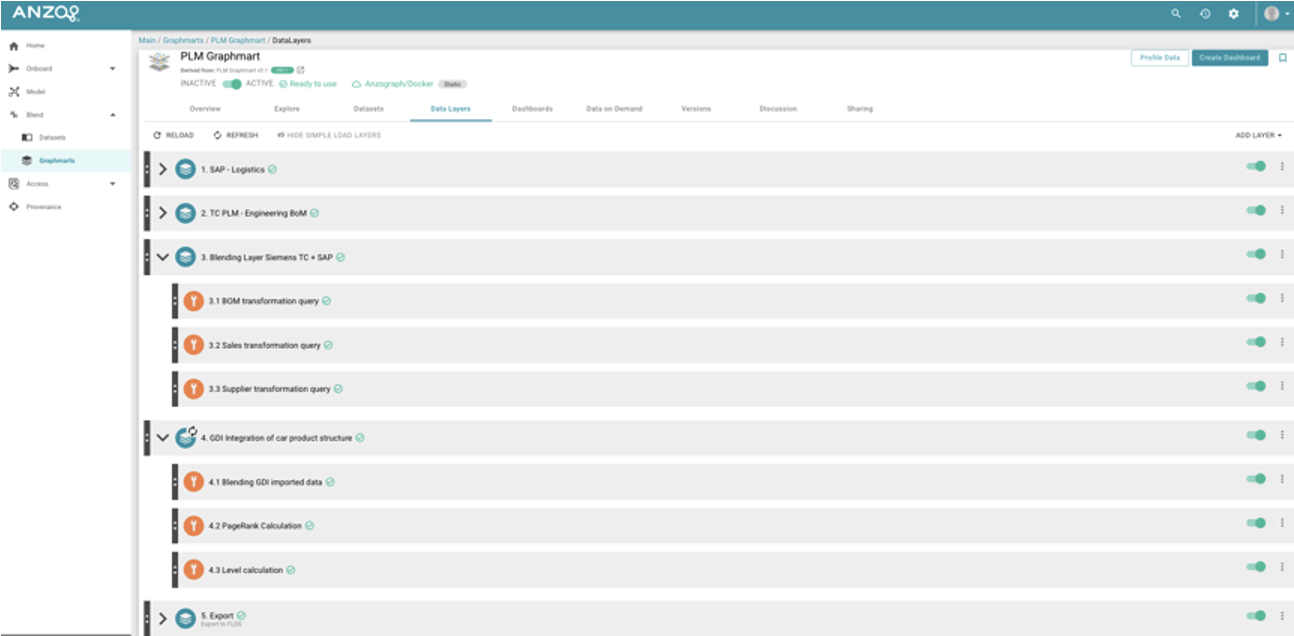
Here is an example Graphmart. You can see the layering of different SPARQL queries grouped by the kinds of operations they perform, and how they can be switched off and on.
Let’s look at the 5 most important variables to consider when working with a Knowledge Graph:
-
Data Mapping
-
Validate sources have expected data schemas used in the mapping logic
-
Describe mapping logic of data from relational sources to target business ontology
-
-
Validation
-
Validation of data model against meta model
-
Validation of data model against business logic outside of ontology
-
-
Knowledge deduction
-
Based on ontological concepts
-
Custom-rule inferencing
-
-
Defining complex procedures by combining previous steps
-
Advanced: Managing your RDF Triple Store
A Graphmart has a set of features to make SAPRQL queries even more powerful and intelligent than they already are by nature without using any other language or standard. Let's take a closer look on these tasks one by one.
Mapping
Assume you want to map the data from the tables below to a target ontology.
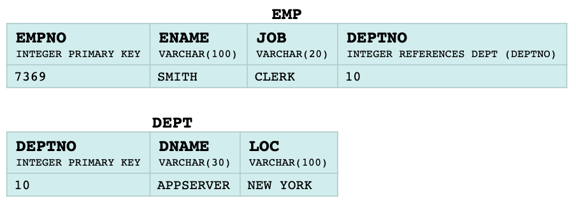
First thing you need to ensure is that the source data did not change since the user defined the mapping. Load and mapping layers rely on the consistency of the schema of data sources. If the schema changes e.g. because a column has been removed or changed the mappings and transformations might have to be adjusted.
The underlying data schema can be validated by a simple SPARQL ASK Query that would access the data directly in the source database:

Ask queries return a boolean result indicating if the pattern specified in the WHERE clause matched any result or not. You can specify what action, if any, you want Anzo to take if this validation step fails (e.g. do nothing, let layer fail, let Graphmart fail, notify user etc.).
After validating the source data schemas lets take a closer look at the mapping itself. In the example below one can see the mapping performed using R2RML and using SPARQL.
Mapping to target ontology with R2RML

Mapping to target ontology with SPARQL in Anzo

The virtualisation SERVICE call makes it very easy to define the mapping in SPARQL and virtualise the data from the relational sources without an increase of the query complexity or the necessity to use another standard.
Validation
Validation of imported data is a crucial part of working with Knowledge Graphs. Essentially we create meta models in form of ontologies that represent the business logic behind the data and then we validate the imported data against these ontologies. A typical example would be defining the domain of a predicate like only objects of type :Person can have a ex:socialSecurityNr . You can use Anzo’s predefined Graphmart layers to do that. All you need to do is to specify in a parametrised SPARQL query, ?class-es from what ontology you want to validate against.

Some things are easier to express and validate using SHACL than OWL, which is why a lot of people like to use it. It is anther W3C standard used to express restrictions on classes.
Validation with SHACL

Again - you could use Graphmart Validation steps to write user-specific ASK queries and decide in the UI what shall happen if a constraint is violated or map the violations to a quality control ontology as shown in the example below.
Validation with SPARQL

Knowledge Deduction
Knowledge deduction or inferencing is the process of making implicit knowledge explicit based on inferencing rules. There are many rule sets like RDFS+, OWL 2 RL and inferencing engines and reasoners like TopSPIN, FaCT++ and Pellet available on the web.
But all we care about as Knowledge Graph Engineers and Business Users is to deduce new knowledge based on (a) ontological concepts and (b) custom business rules.
And again - you can do it all in a Graphmart with just SPARQL. Probably not too shocking anymore if you’ve read the article until here. Anzo supports RDFS+ as well as OWL 2 RL rule sets for inferencing out of the box and has a lot of flexibility.

Not only can you specify the named graphs with data to be considered during the inferencing step but also the rules applied, and thus chain multiple separate inferencing layers in your Graphmart and turn them on and off or change order. Whatever you want. A more detailed documentation can be found here: RDFS-Plus Inferencing
For custom rules, you can again define a Layer in a Graphmart that would contain one or more SPARQL INSERT queries. 
Complex procedures
Since SPAQRL is a query language and not a programming language the definition of execution conditions of a query, the order of queries and the versioning can be very tricky. In a Graphmart SPARQL queries are provided all these features through metadata specified in the UI.
Managing your RDF Triple Store
The best comes last. Every object in Anzo is stored in RDF. Ontologies, Graphmarts, Layers, Users, Permissions etc. In other words you can even use SPARQL to define Access Rights.
The beauty of Knowledge Graphs is that they make data management and analytics easy and intuitive. SPARQL is so easy to learn because it follows human intuition to describe patterns in graphs. Anzo gives you the possibility to learn less languages and standards outside of SPARQL and at the same time perform more complex and intelligent operations on your Enterprise Knowledge Graph.
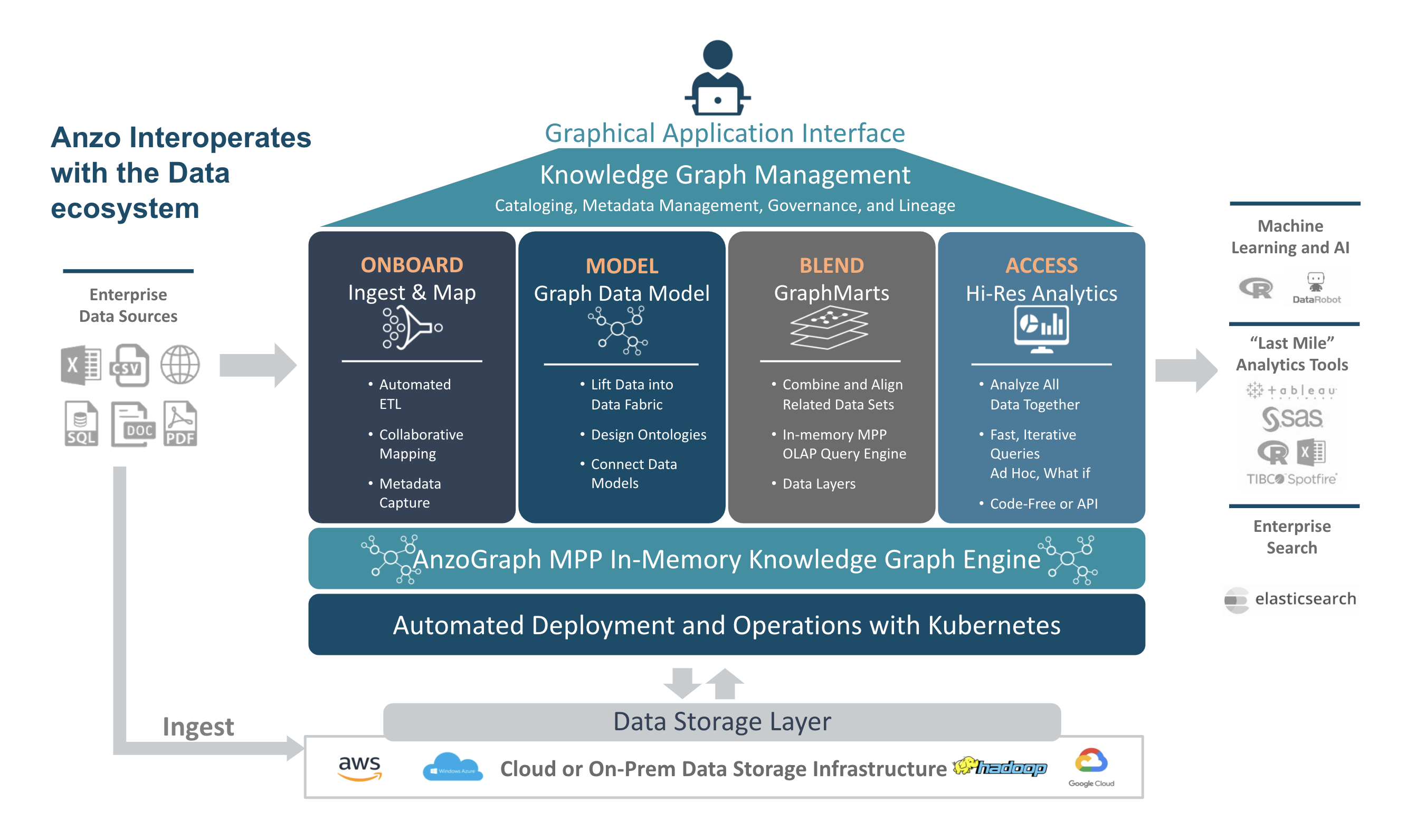
Anzo Architecture Overview