What it takes to integrate and analyze disparate data in a modern infrastructure
If you are a practitioner in the analytics space and a believer that enterprise data can be a huge strategic asset, you also know that the devil is in the details. Over the last thirty years, we've had one thing that repeatedly impedes the use of enterprise data for the greater good of our company, and that is that it is often siloed. If your company has grown via acquisition or simply just didn't have a great data governance strategy as it grew, chances are that leveraging enterprise data is going to be painful. The data silos impede everything from simple reporting to data science to machine learning.
While there have been many methods attempted to solve the disparate data problem, a knowledge graph is the most modern and best way to harmonize enterprise data. All data, data sources, and databases of every type can be represented and operationalized in a knowledge graph. It provides a flexible platform to integrate all of your data with the ability to perform analytics – not only the legacy data warehouse kind, but connected analytics, geospatial analytics and machine learning all come together to deliver new insights.
What it takes to Build a Knowledge Graph
Graph databases are considered a powerful tool in creating knowledge graphs, since their flexible data model is more forgiving about schemas and sparse data. Rather than making your data conform to a series of tables in your data warehouse, you can load data into subject-predicate-object triples, also known as nodes and edges in the property graph world. In addition, building the relationships between one or more databases is a strength of the graph model.
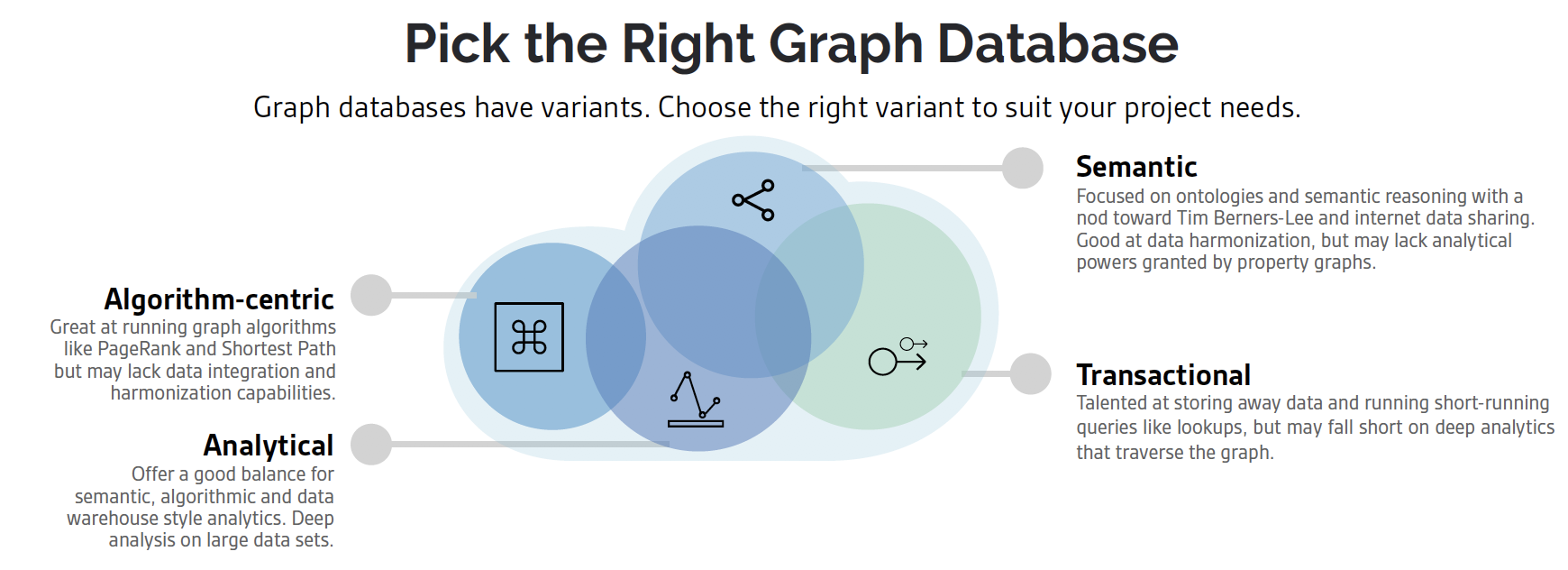
Which graph database is the right tool for this task, however? You might think of the graph database market as one type of technology, but it really is not. The industry has developed various methods of doing the critical tasks that drive value graph databases. There are the following flavors of graph:
Algorithm-centric – Focused on performing graph algorithms with speed and scalability
Semantic – With a nod toward Tim Berners-Lee and his approach of sharing data on the Web as easily as we share internet pages.
Transactional - Graph databases that are concerned with ingesting data quickly and performing fast running analytics.
Analytical – Graph databases that are focused on analytics, like BI-style analytics, multi-hop connected analytics and big data analytics.
No database is purely only one of these types, rather they tend to lean toward algorithms or transactions, or semantics. Step one, therefore is to consider your knowledge graph, its goals, the scalability necessary to either ingest or analyze data and begin with the right solution.
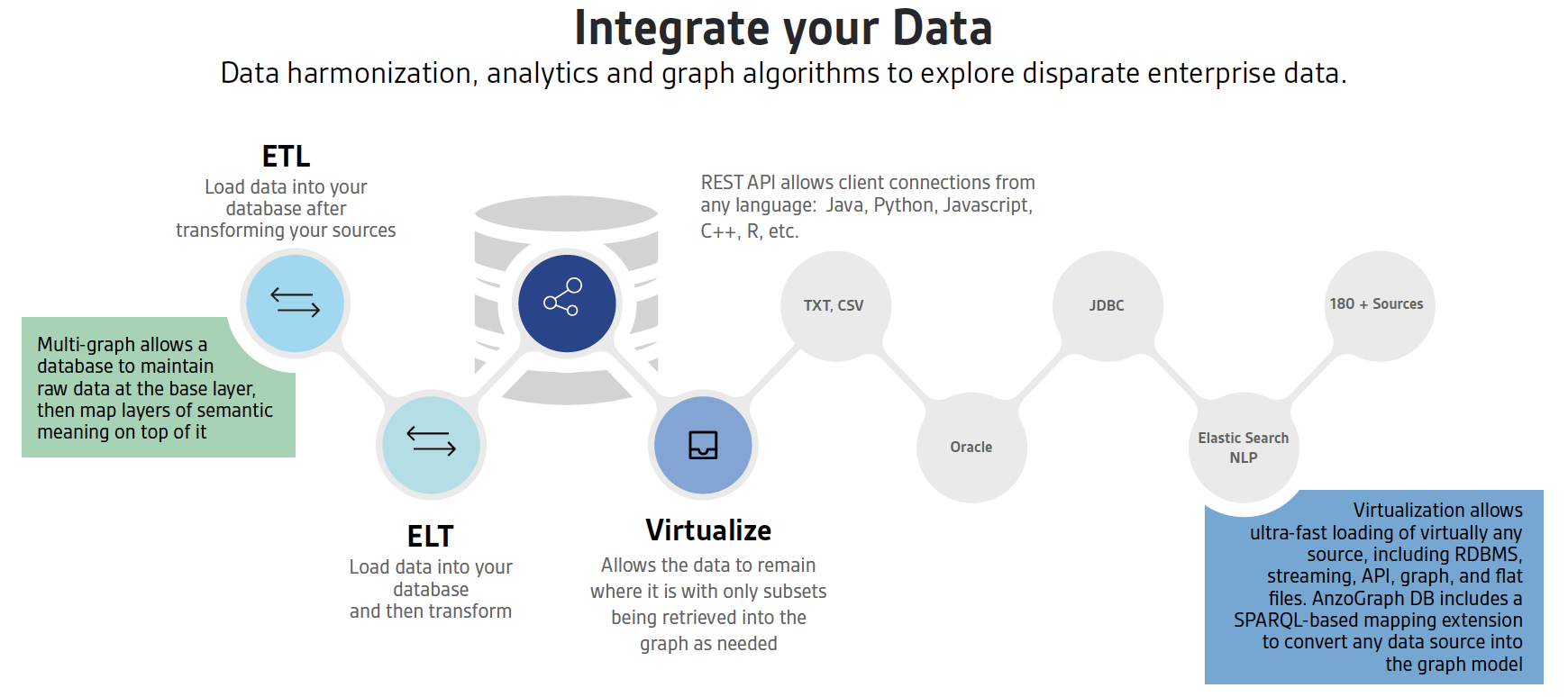
The next step in setting up a knowledge graph is to consider how to integrate data. This can happen with various methods.
ETL - You can simply load your data quickly in your graph database ETL style and use it right away. Practitioners may massage the data in some other tools and ingest it via ETL. Enterprises have used ETL for years, but it does tend to necessitate creating copies of data, and it's this duplication of data that can eat up resources in your company.
ELT- If clean data is not your source, you can also load your data ELT-style where you load the raw data using the databases multi-graph feature, massage it with the database for data quality and store the data more permanently in a permanent data layer. The multi-graph feature of a graph database facilitates this data loading style, yet it's common in the graph database world to have a solution that can only handle one graph at a time. Make sure the database you choose can handle more than one set of data at a time.
Virtualization- The third method is virtualization, which may or may not load the data into the database, but makes the data appear to the database engine as if the silos don't exist. Virtualization means the database can handle an abstraction of data for any given task. With virtualization the data is often used in-place for analytics and therefore your solution must have some understanding of native data formats like Oracle, Postgres, Hadoop, et al. A knowledge graph doesn't necessarily destroy silos of data, as some data can be left where it is and still provide analytical value.
If there's one trade-off with virtualization is that it tends to be less performant. However, depending on your use case, you may not need a sub-second query response. In other words, it may be simply fine for the analytics to take a few extra seconds to complete vs loading data. Also, you might consider virtualization of only smaller data sets for performance. Perhaps there is only a column or two that you need from the virtualized sets for your analytics. Virtualization beats having to make multiple copies of your data.
Once you've instantiated your database and loaded (or virtualized) data, the next barrier in relishing your knowledge graph will be analytics. Knowing the kinds of analytics you can run, how long they will take and what level of scale they can handle is a crucial planning step. A knowledge graph platform supports not only the traditional data analytics, but a much wider and deeper range than a plain graph database.
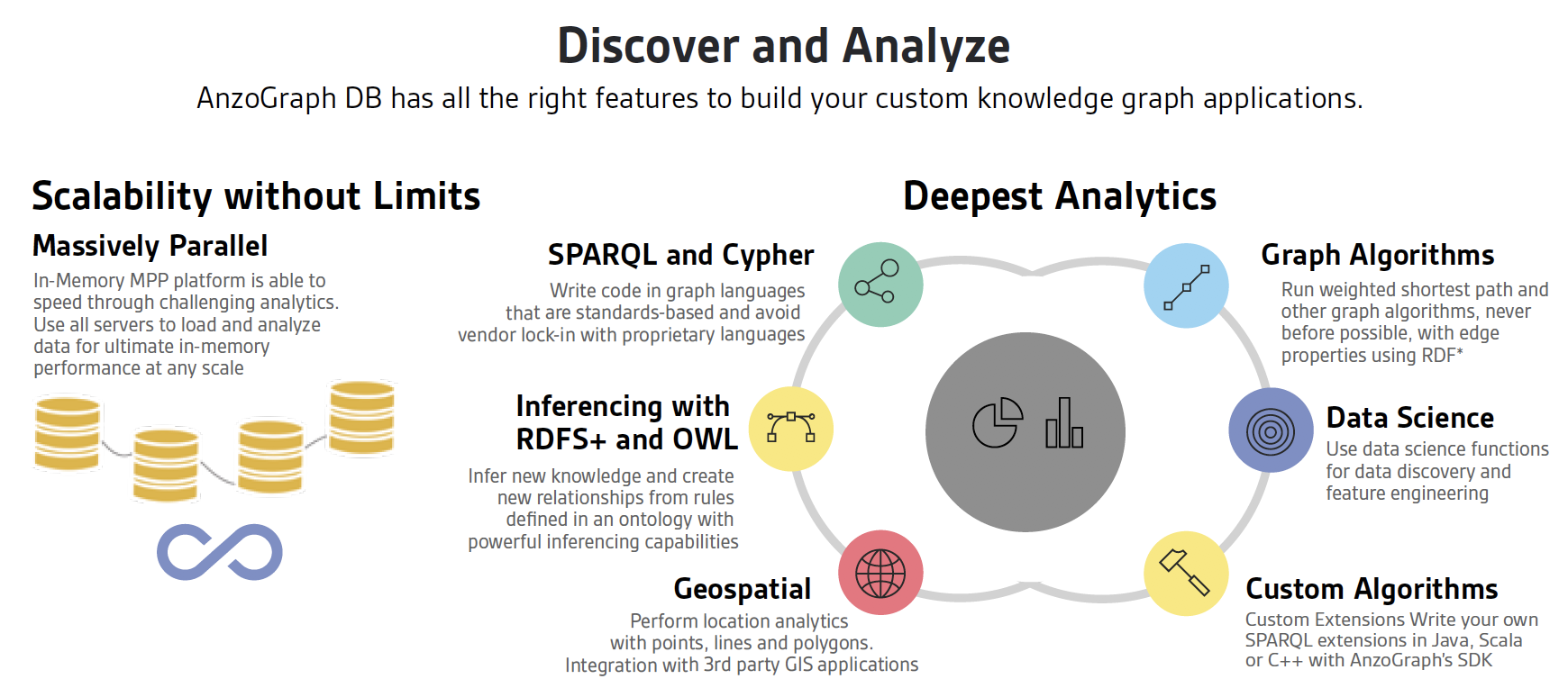
Scalability without Limits
Some graph databases hardly scale while others scale in different ways. Does the database scale for transactions and users? Can it handle billions of triples and traverse the database with aggregate functions? If you have a performance problem can you add more computing power to overcome it?
To test this capability, there are tests you can run. Simple aggregate functions like counts and average are one way. For a more complete test, you can turn to the SPARQL version of TPC-H, and independent, non-profit benchmark designed for data warehouse.
Deepest Analytics
A knowledge graph, unlike a plain graph database, has all the tools to help you turn diverse raw data into knowledge and it does that with analytical functions. When it comes to analytics, there is more to it.
SPARQL and Cypher - It starts with a standardized code base like SPARQL or Cypher where you can take what you know from other solutions and transfer that experience to a new tool. You don't have to learn a proprietary language and therefore you won't be locked in.
Inferencing with RDFS+ - Knowledge graphs stores entities and relationships in data and allows users to search, analyze and use this connected data to accelerate vital new discoveries. An inferencing engine will let you leverage relationship libraries like HL7 and FIBO, or create your own proprietary relationships. Commonly, enterprises track equivalencies, classes and subclasses, context given the source of the data and allow you to make inferences. However, you won't find this in many property graphs as a native tool.
Geospatial - Graph databases seem to be custom made for geospatial analytics. Where traditional databases can be cumbersome when dealing with relationships between places and people, things or events. A graph database is particularly adept at modeling places as interconnected entities, allowing you to explore these relationships through analytics. Not all graph databases support geospatial, however.
Graph Algorithms - Graph algorithms like Pagerank, Connected Components, Triangle Enumeration, Shortest Path are powerful to have, but you won't find them in many of the legacy semantic databases.
Data Science Functions – You can extend SPARQL or Cypher analytics with data science algorithms like correlation, profiling, distributions and entropy analysis to name a few. Use these algorithms for data preparation and data quality as you bring together your diverse sources.
Custom Algorithms – Create your own algorithms that run in our graph engine. Use this crucial capability, particularly if you are building your own application for genomic study or stocks prediction, to name a few. Not all graph databases let you customize algorithms that leverage a cluster of computing power to run.
Why AnzoGraph DB Makes Sense for Knowledge Graph
In terms of a choice for knowledge graph engines, AnzoGraph DB provides the right balance, offering semantics, data harmonization, graph algorithms, BI-style analytics in a highly scalable, massively parallel platform.
AnzoGraph DB offers highly performant in-database data loading, making loading and transforming your data fast and easy. Alternatively, don't load the data at all and keep it in place with our virtualization capabilities. AnzoGraph DB Free Version is available on AnzoGraph.com, free for commercial and non-commercial use for up to 16 GB.