At Gartner's Data & Analytics Summit 2017, Alok Prasad, President of Cambridge Semantics, was joined by Peter Horowitz of PricewaterhouseCoopers for their session entitled “Accelerating Insight:...
Earlier this month, the Cambridge Semantics team set off for Grapevine, Texas, for the Gartner Data & Analytics Summit 2017 to join more than 3,000 big data industry customers, Gartner analysts and...
“If you know the enemy and know yourself, you need not fear the result of a hundred battles. If you know yourself but not the enemy, for every victory gained you will also suffer a defeat. If you...
The nature of the insurance industry is changing quickly, and much of that change is being attributed to big data and analytics. In fact, a Research and Markets report on the global insurtech market...
The data lake is a modern and rapidly evolving data architecture. It promises ubiquitous access to enterprise data with compelling benefits in terms of cost and agility. Yet, in many cases, this...
At Strata+Hadoop World 2016, the concept on everyone's mind was the Data Lake. Fortunately, Marty Loughlin, our Vice President of Financial Services, was there to discuss how Smart Data Lakes are...
Last month, the Cambridge Semantics team set off to New York City for Strata + Hadoop World 2016, or what Wired likes to call, “the lollapalooza of big data conferences.”
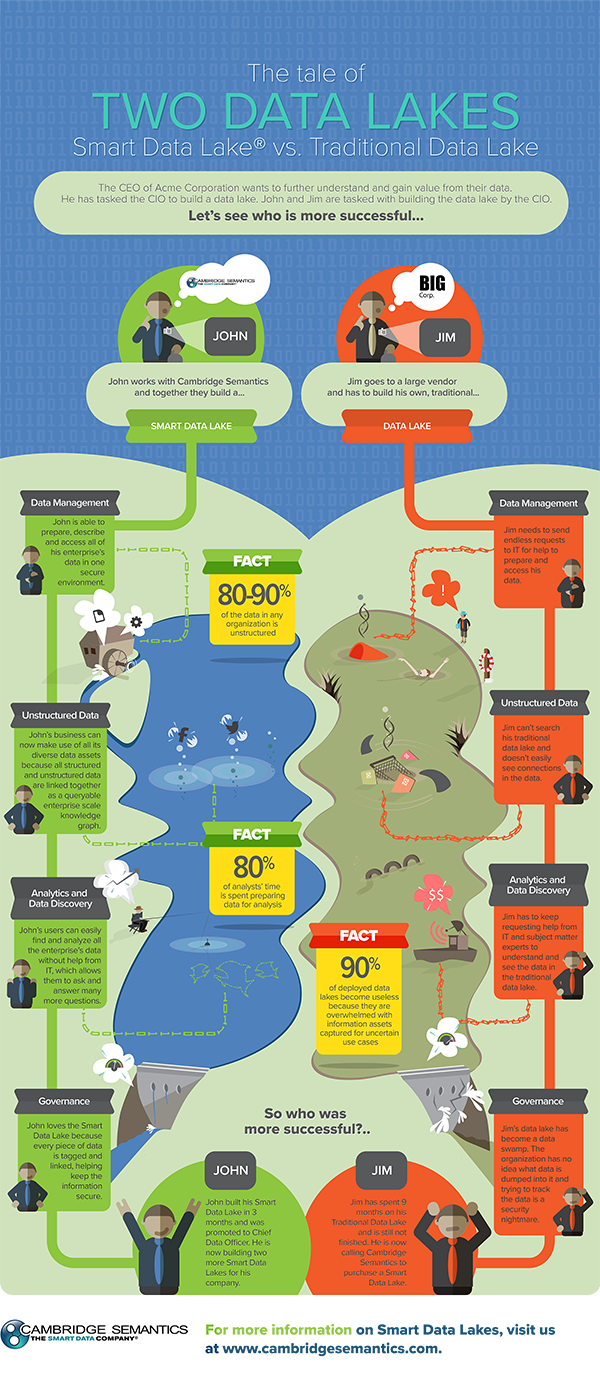
The CEO of ACME Corporation wants to further understand and gain value from their data. He has asked the CIO to create a data lake. John and Jim are then tasked with building the data lake by the...
Data originates everywhere in the healthcare industry – in laboratories, within insurance agencies, in Electronic Medical Record (EMR) systems, etc. – and each of these sources represents a valuable...
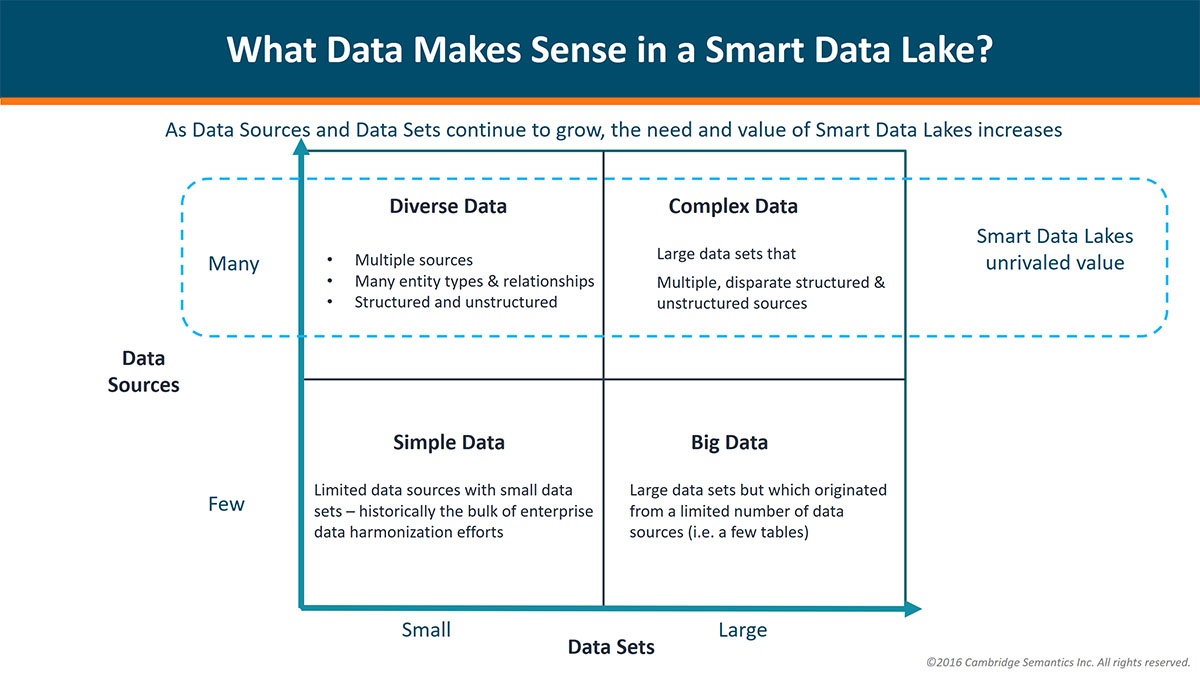
In recent years, the concept of a “data lake” has grown in popularity across the world of big data. From financial services to healthcare, companies are recognizing the value they can bring to data...