At Cambridge Semantics, we have watched the explosion of AI awareness in the last year with interest. Nearly every tech leader considering our knowledge graph platform, Anzo, is also actively...
“In current data management technology environments, the logical data structure of a relational database management system cannot totally satisfy the requirements for a full conceptual definition of...
In today's data-driven world, businesses and organizations face the challenge of efficiently organizing and harnessing vast amounts of information to drive insights and informed decision-making....
We recently shared with the world how generative AI matched with knowledge graph technology (in our example via Knowledge Guru) opens a world of intuitive, self-service analytics which can be...
In the rapidly evolving world of artificial intelligence, there's a powerful tool called the Knowledge Guru that is revolutionizing the way we access and utilize enterprise knowledge. This...
To begin, consider the following definitions provided from a 2022 U.S. Army Request For Information (RFI). (Emphasis added.)
We recently held a webinar titled, The Future of Data Integration, where our Principal Presales Engineer Greg West shared why graph technology has become the best solution for data-driven...
Corporate CIOs make dozens of critical decisions every day, and while many will be made with instinct and experience others will depend on deep insight built on data analysis. These decisions not...
We recently came across an article by Transforming Data with Intelligence (TDWI) that really surprised us. Sentence by sentence, paragraph by paragraph, our head nods seemed to be dipping into...
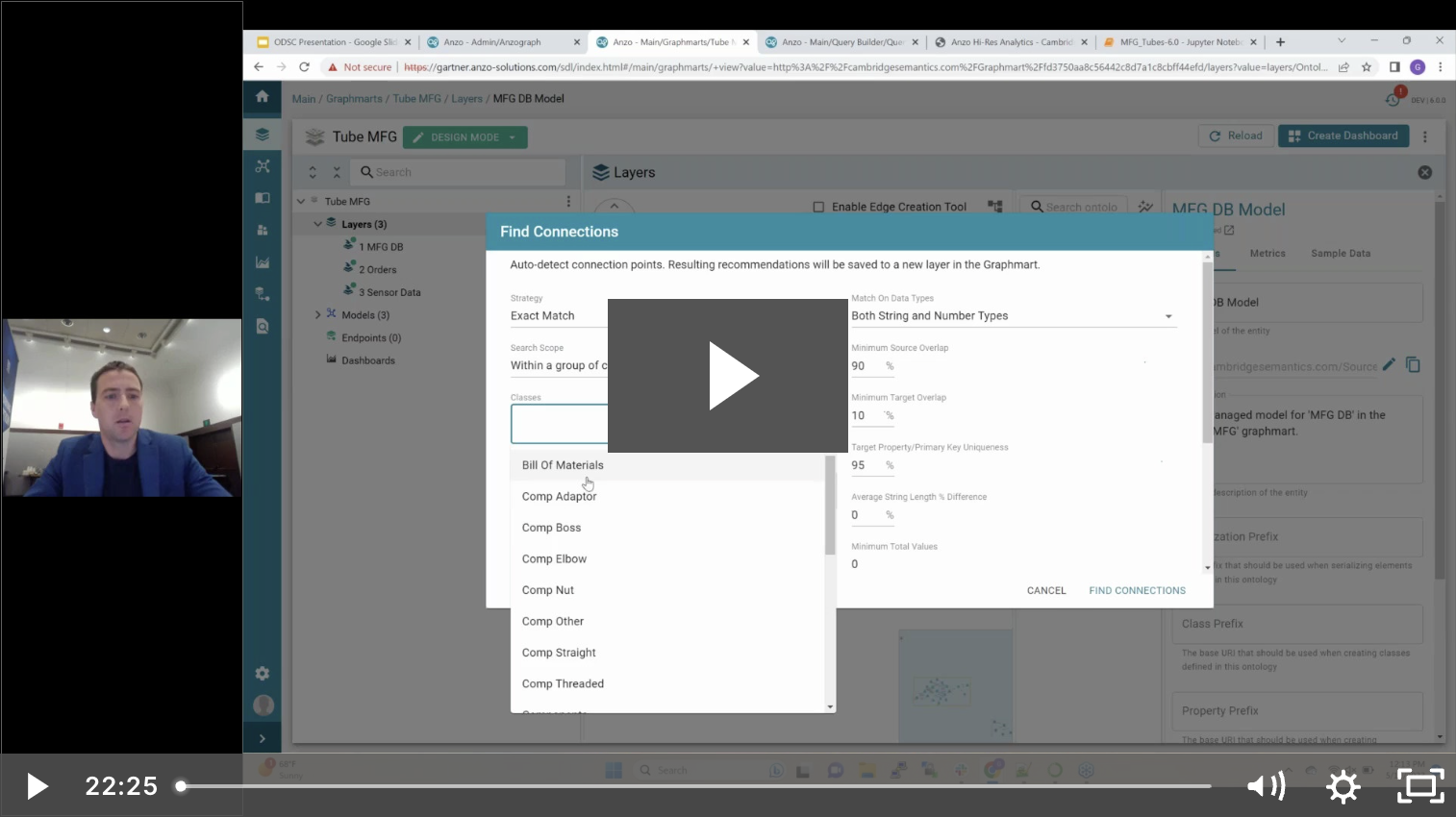
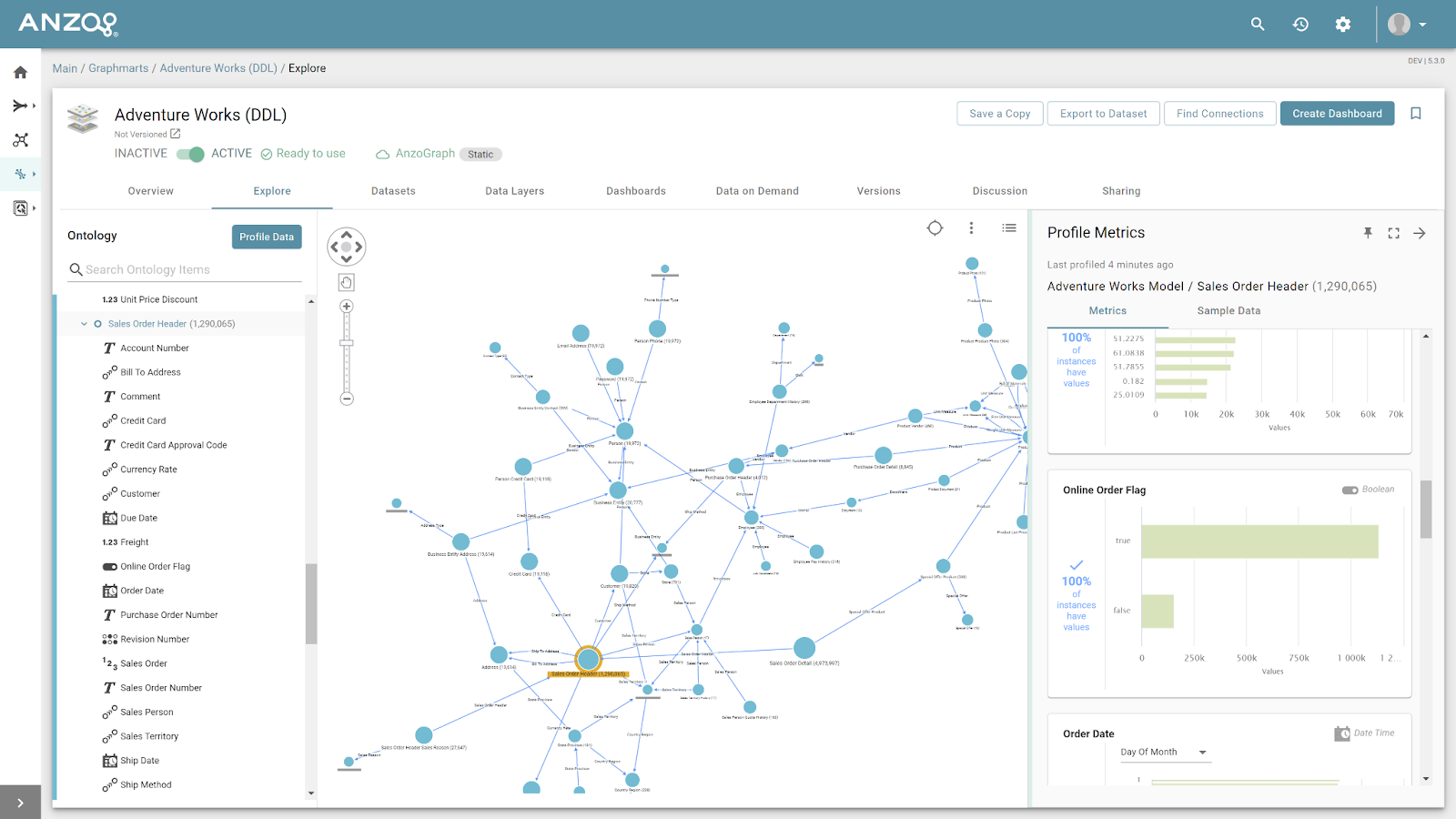
We’re pleased to announce the release of Anzo® 5.3. This is a major release full of exciting capabilities to further enhance the leading knowledge graph platform solution, Anzo. Foremost, it’s now...