Last month, the Cambridge Semantics team set off to New York City for Strata + Hadoop World 2016, or what Wired likes to call, “the lollapalooza of big data conferences.”
The largest conference of its kind, Strata + Hadoop World brings together data scientists, innovators and executives to catch up on emerging techniques and technologies in the data analytics space. Discussion topics included, but were not limited to, data-driven business, data science and advanced analytics, Hadoop use cases, security, visualization and user experience.
Aside from managing our booth, we spent the majority of our time interacting with attendees, media and fellow exhibitors, and discussing the data issues that are shaping industries from finance and healthcare to retail, manufacturing and government. From our conversations, we identified one particular theme that resonated across the expo floor: the data lake. In fact, a quick look at Google Trends for the search term "data lake" shows a steady increase in interest in this concept over the last 5 years:
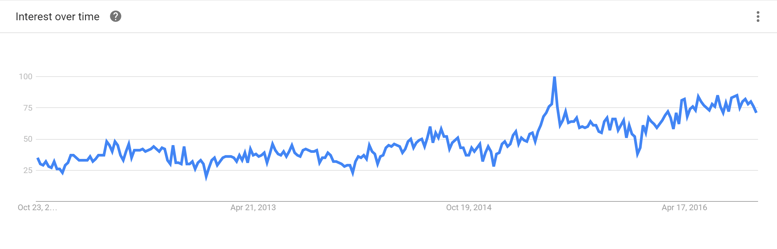 Over the past few years, the term “data lake” has grown from a mystery to a familiar big data trend, leading many data companies to develop solutions accordingly. Upon reviewing these vendors ourselves, as well as through discussions with colleagues and partners, we came to the conclusion that no one in the space is covering the entirety of data lake solutions like Cambridge Semantics.
Over the past few years, the term “data lake” has grown from a mystery to a familiar big data trend, leading many data companies to develop solutions accordingly. Upon reviewing these vendors ourselves, as well as through discussions with colleagues and partners, we came to the conclusion that no one in the space is covering the entirety of data lake solutions like Cambridge Semantics.
Cambridge Semantics’ Anzo Smart Data Lake® solution is built for end-to-end graph-based data preparation, management, integration, analysis and governance. It is an all-encompassing solution unique to Cambridge Semantics that provides users with self-service data discovery, analytics and visualization capabilities across all entities and relationships in the data lake.
In addition, our VP of Financial Services Marty Loughlin held a presentation during Strata + Hadoop about our Anzo Smart Data Lake. Using what’s known as semantic web technology combined with a graph-based query engine, Marty discussed how the Anzo Smart Data Lake allows data lakes to be accessed and queried by anyone in the enterprise seeking answers to business questions, enabling the democratization of data discovery and data science.
Aside from data lakes, another topic of conversation at the Cambridge Semantics booth was graph-based business intelligence analytics. For more information about our Anzo Graph Query Engine, the most advanced in-memory graph analytic engine, visit our website.
Overall, Strata + Hadoop 2016 was a very successful event for the Cambridge Semantics team. Our in-depth conversations with industry peers were both invaluable and informative as we look to continue down the road. We were thrilled to witness the growth of the data lake and look forward to contributing to its influence over the next year.
To learn more about smart data lakes, watch our webinar "Smart Data Lakes: Game Changing, Graph-Based Data Discovery, Analytics and Governance for the Enterprise".
