Digital transformation and regulatory compliance are driving challenging new demands for access to enterprise data in large Financial organizations. Most organizations are struggling to meet these...
Most large financial organizations are wrestling with fundamental data management challenges. Traditional technologies are struggling to meet these challenges and they demand a new approach. Forward...
Deploying a big data platform as a data warehouse replacement offers compelling cost and agility benefits. However, it is not an "out of the box" experience. To manage the data lifecycle from source...
Earlier this month, the Cambridge Semantics team set off for Grapevine, Texas, for the Gartner Data & Analytics Summit 2017 to join more than 3,000 big data industry customers, Gartner analysts and...
With compelling business use cases, adoption of open industry standards and enterprise deployment of high performing scalable platforms, 2016 was a breakout year for the adoption of semantic graph...
The data lake is a modern and rapidly evolving data architecture. It promises ubiquitous access to enterprise data with compelling benefits in terms of cost and agility. Yet, in many cases, this...
"So what?" you might say. Another hyperbole-fueled headline in tech is hardly a notable event. To answer, let's start with what we did.
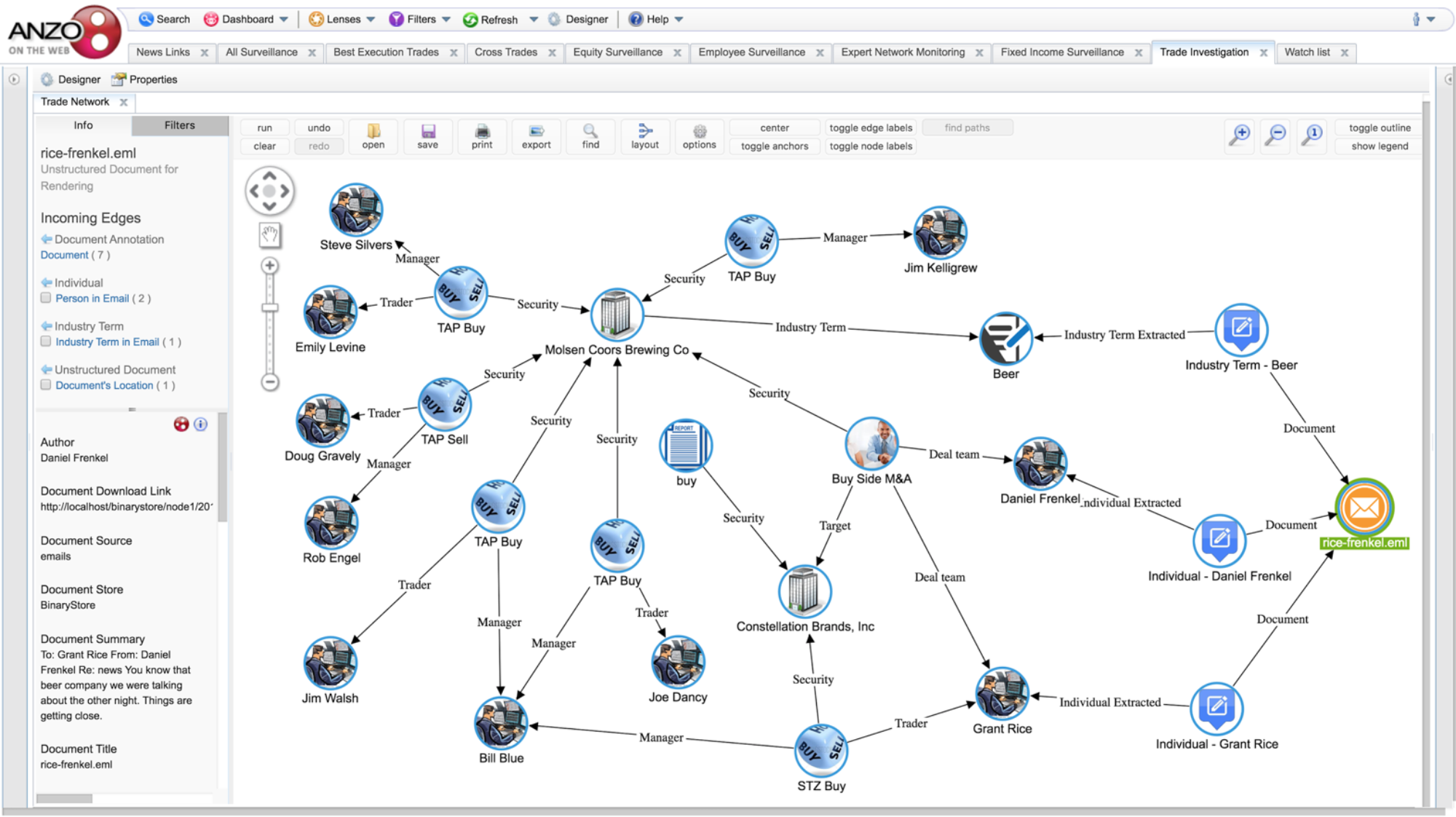
The challenge for analysts seeking trading opportunities that outperform the market is not a lack of information. It is an over-supply of information from widely disparate sources. How do you sift...
We are at an inflection point in the financial services industry. The evolving and overwhelming demands of regulatory compliance have forced organizations to acknowledge the need for data governance...
State Street Bank, The EDM Council, Dun & Bradstreet, Wells Fargo and Cambridge Semantics completed an engagement to harmonize State Street's Interest Rate Swap data with Dun & Bradstreet's entity...